OmnIoT SoftHub is a way of creating IoT edge applications quickly without any programming. It runs on Raspberry Pi hardware (2, 3, 4, or Zero/W) and detects iBeacon, AltBeacon, and EddyStone beacons ‘out of the box’. The authors have told us they are interested in integrating other Bluetooth sensor types.
The platform allows sending of data to many 3rd party MQTT brokers. It logs data to internal or attached storage and can also decode data into a variety of data formats. Thresholds can be created to cause events, for example, sending alarm emails or SMS messages direct from the platform itself.
It’s free for personal use and one-off company projects. It only needs to be licensed if you are going to re-sell it as part of a solution.
There’s a new in-depth article at PC Mag on how Carnival use beacons, based on Bluetooth and NFC, on cruise ships. As the article says, “it provides an excellent case study in how to use technology to enhance your customer’s experience”.
The beacons are branded as ‘OceanMedallion’ and allow:
Guests to unlock their stateroom
Guests to pay for drinks or items in shops
Guests to play in the casino
Housekeeping staff to keep track of whether or not the stateroom is occupied
7,000 sensors throughout each ship detect the beacons and 4000 interactive portals provide information for guests. A mobile app can also be used that can help navigate about the ship and find fellow passengers.
Beacons provide a way to eliminate friction in the passenger experience. The software system uses edge devices to perform operations close to where the user has been detected so as to reduce latency and network traffic. Nevertheless, the system attempts to centralise data so as not to replicate information.
The system provides Carnival with lots of useful data on guest preferences, transactions (for billing) and preferred areas of the ship. Aggregated information might be used to determine heavily used areas (for maintenance), pinch points and redundant areas of the ship to feed into improvements to the ship.
The latter part of the article explains how, when there’s a problem in a smart factory, it can have large affects. The onus is on technology that can predict problems before they cause downtime. This leads to questions where the data processing should be the observations that:
“In the long-run, pushing everything to the cloud doesn’t work from a cost point of view.”
and
“Once you aggregate and compress the data, for example, to ‘max,’ ‘min,’ ‘outliers,’ ‘average’ and stuff like that, you lose the ability to run data science”
Such situations are the focus of our new Sensor Cognition™ technology that can provide machine intelligence at the edge.
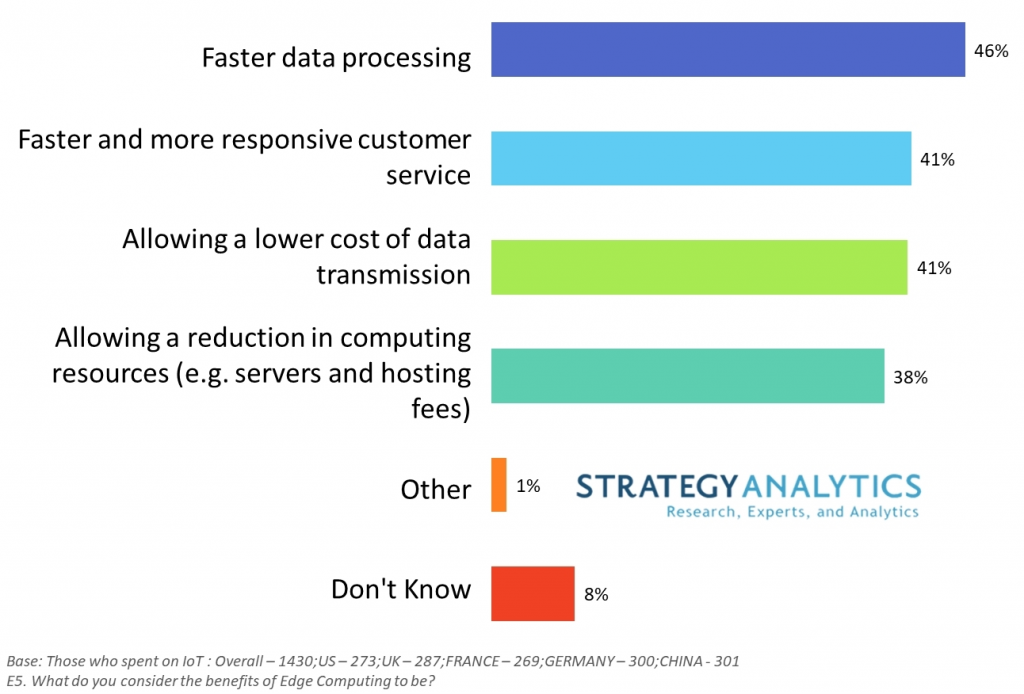
Strategy Analytics have a new press release on Edge Computing on the Rise in IoT Deployments. Edge computing is where data is processed close to where it originates for better network use, reduced traffic/storage and faster detection/notification times. Strategy Analytics end user research shows that 44% of companies are currently using edge computing, in some form, in their deployments.
Read about SensorCognition™, our Edge gateway with machine learning.
The traditional IoT strategy of sending all data up to the cloud for analysis doesn’t work well for some sensing scenarios. The combination of lots of sensors and/or frequent updates leads to lots of data being sent to the server, sometimes needlessly. The server and onward systems usually only need to now about abnormal situations. The data burden manifests itself as lots of traffic, lots of stored data, lots of complex processing and significant, unnecessary costs.
The processing of data and creating of ongoing alerts by a server can also imply longer delays that can be too long or unreliable for some time-critical scenarios. The opposite, doing all or the majority of processing near the sensing is called ‘Edge’ computing. Some people think that edge computing might one day become more normal as it’s realised that the cloud paradigm doesn’t scale technically or financially. We have been working with edge devices for a while now and can now formally announce a new edge device with some unique features.
Another problem with IoT is every scenario is different, with different inputs and outputs. Most organisations start by looking for a packaged, ready-made solution to their IoT problem that usually doesn’t exist. They tend to end up creating a custom coded solution. Instead, with SensorCognition™ we use pre-created modules that we ‘wire’ together, using data, to create your solution. We configure rather than code. This speeds up solution creation, providing greater adaptability to requirements changes and ultimately allows us to spend more time on your solution and less time solving programming problems.
However, the main reason for creating SensorCognition™ has been to provide for easier machine learning of sensor data. Machine learning is a two stage process. First data is collected, cleaned and fed into the ‘learning’ stage to create models. Crudely speaking, these models represent patterns that have been detected in the data to DETECT, CLASSIFY, PREDICT. During the production or ‘inference’ stage, new data is fed through the models to gain real-time insights. It’s important to clean the new data in exactly the same way as was done with the learning stage otherwise the models don’t work. The traditional method of data scientists manually cleaning data prior to creating models isn’t easily transferable to using those same models in production. SensorCognition™ provides a way of collecting sensor data for learning and inference with a common way of cleaning it, all without using a cloud server.
Sensor data and machine learning isn’t much use unless your solution can communicate with the outside world. SensorCognition™ modules allow us to combine inputs such as MQTT, HTTP, WebSocket, TCP, UDP, Twitter, email, files and RSS. SensorCognition™ can also have a web user interface, accessible on the same local network, with buttons, charts, colour pickers, date pickers, dropdowns, forms, gauges, notifications, sliders, switches, labels (text), play audio or text to speech and use arbitrary HTML/Javascript to view data from other places. SensorCognition™ processes the above inputs and provides output to files, MQTT, HTTP(S), Websocket, TCP, UDP, Email, Twitter, FTP, Slack, Kafka. It can also run external processes and Javascript if needed.
With SensorCognition™ we have created a general purpose device that can process sensor data using machine learning to provide for business-changing Internet of Things (IoT) and ‘Industry 4.0’ machine learning applications. This technology is available as a component of BeaconZone Solutions.
The Nordic blog has an informative post on How IoT-Based Predictive Maintenance Can Reduce Costs. It explains how connected sensors can save maintenance costs through reduced downtime. The post provides some examples from the power industry and explains how the same techniques can be used in the tools, retail, distribution and physical infrastructure industries.
As the post mentions, the challenge is how to scale this up. We are told IoT is the solution. Here at BeaconZone, we don’t believe IoT is always the solution, especially where there’s a requirement for higher sensor sampling frequencies. There’s too much data, too much data transfer and too much server processing. It really doesn’t scale. Apart from the waste and cost of these resources, the latency of triggering events based on the data is too high. Instead, look to so called ‘edge’ or ‘fog’ computing where more processing is done nearer the sensors and only pertinent data is sent to other systems.