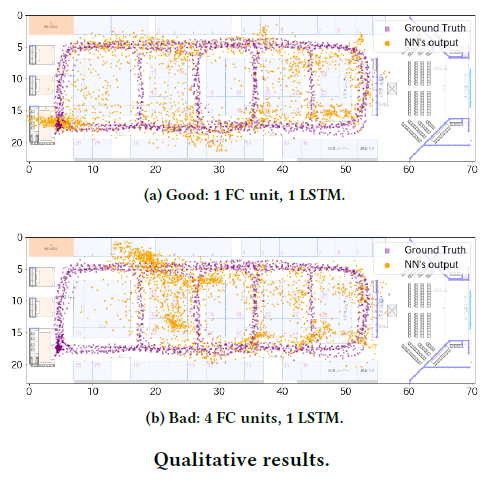
There’s interesting new research into TinyML for On-Device and Edge Analytics in Wireless Networks. The beacon-relevant parts are concentrated around BLE indoor navigation, proximity detection, RF fingerprinting-based positioning and beacon transmission-power control.
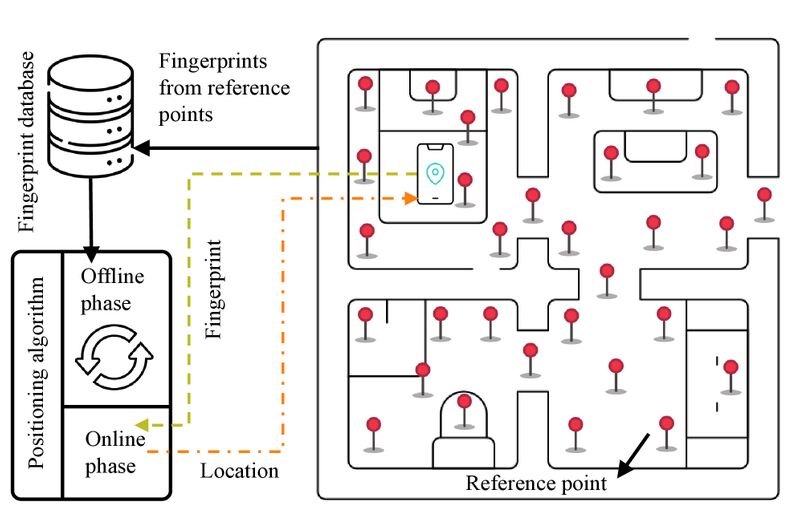
The paper describes RF fingerprinting-based indoor positioning, where radio infrastructure such as Wi-Fi access points, BLE beacons and cellular base stations can be part of the positioning system. It explains that fingerprints are collected in an offline phase, used to train a positioning algorithm, and then used online to infer an asset’s location. The paper says tiny deep learning is attractive here because it can extract features automatically, handle non-linear boundaries in indoor spaces, and run at the edge with lower latency, better privacy and less reliance on a central server. It cites an indoor asset-tracking implementation using BLE beacons that achieved about 88% location-estimation accuracy.
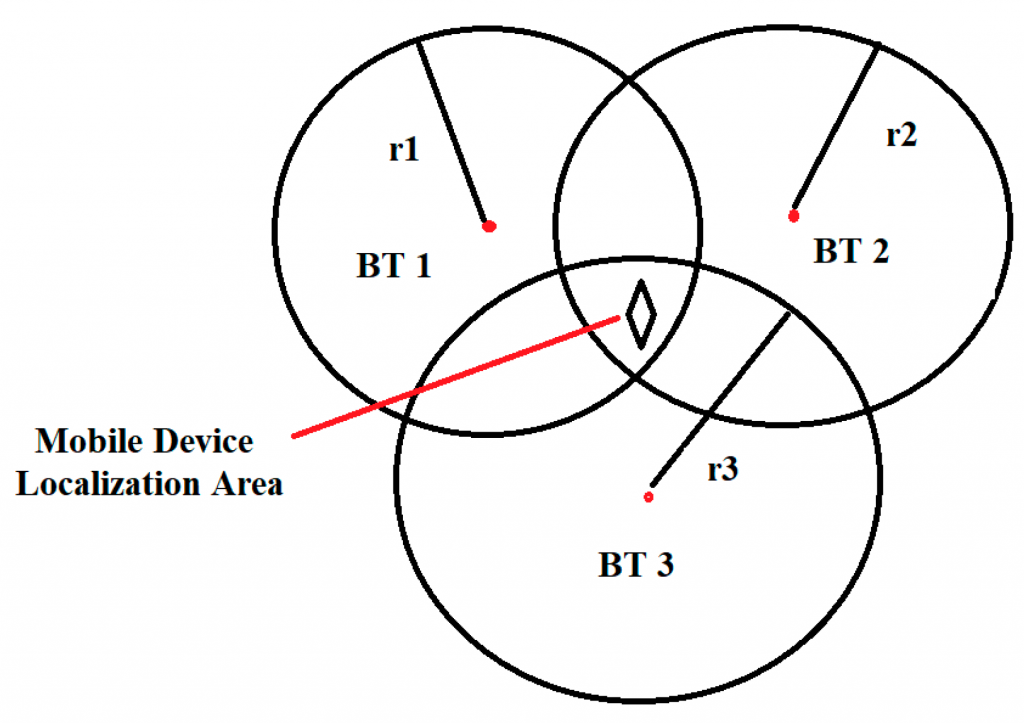
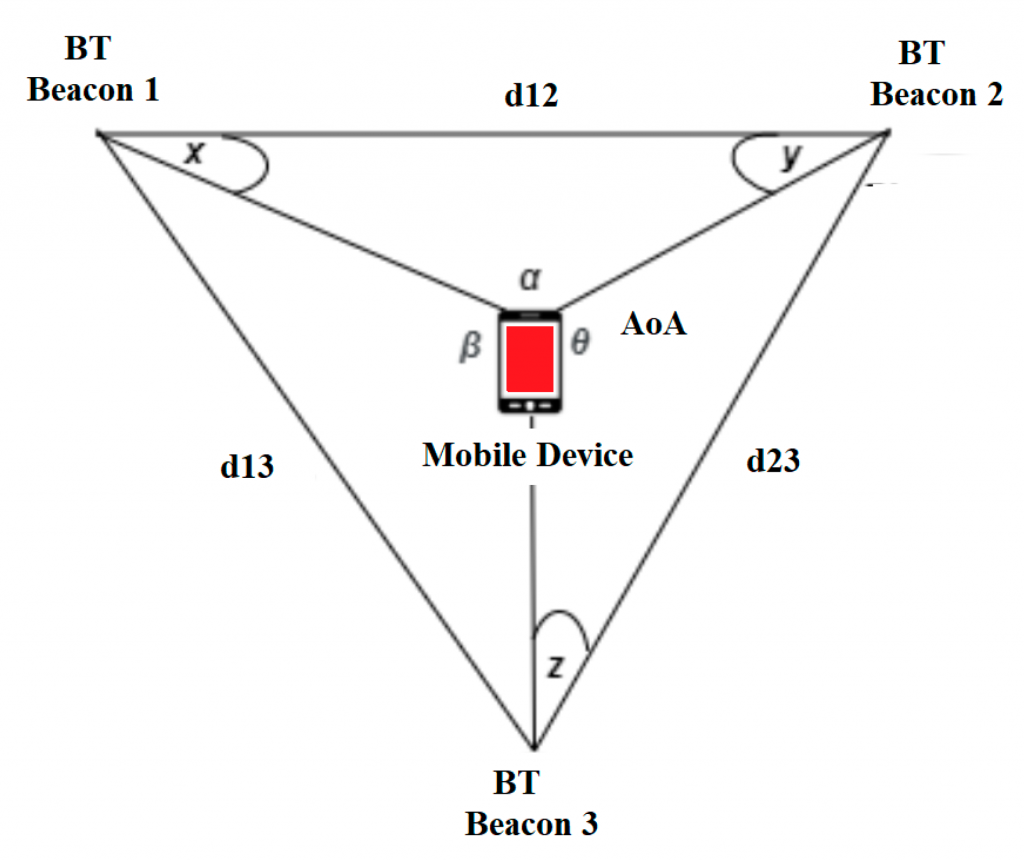
For BLE navigation, the paper treats beacons as especially relevant in indoor places where GPS is unreliable, such as hospitals, shopping centres, factories and university buildings. In that setting, mobile devices estimate their position using RSSI measurements from nearby BLE beacons; RSSI is the received signal power level and is also used to infer proximity between devices.
The main proposed tinyML opportunity is RSSI-based transmission-power management on BLE beacons. The idea is that beacons send periodic messages to mobile user devices, while also using RSSI from other beacons’ transmissions to estimate interference. A tiny reinforcement-learning model could run directly on each beacon, using received signals as the state, transmission power as the action, and a reward based on the resulting RSSI. The purpose is to tune beacon power continuously, reduce interference and improve indoor navigation performance.
The other beacon-adjacent opportunity is improving proximity detection through RSSI-based ranging. The paper argues that classical RSSI ranging is weak because it mostly relies on spatial features and ignores time- and frequency-domain RSSI fluctuations; motion between devices adds fading, reducing confidence and accuracy. It suggests using tiny deep learning on a mobile MCU-based receiver to incorporate broader RSSI features, including time-domain, frequency-domain and statistical characteristics, with the aim of improving distance estimates.
In practical terms, the paper’s message is that BLE beacons are a good fit for tinyML because the intelligence can move closer to the beacon or mobile device.