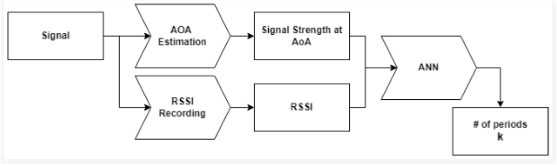
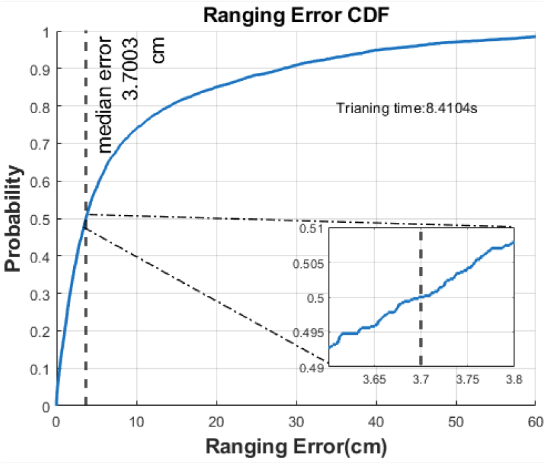
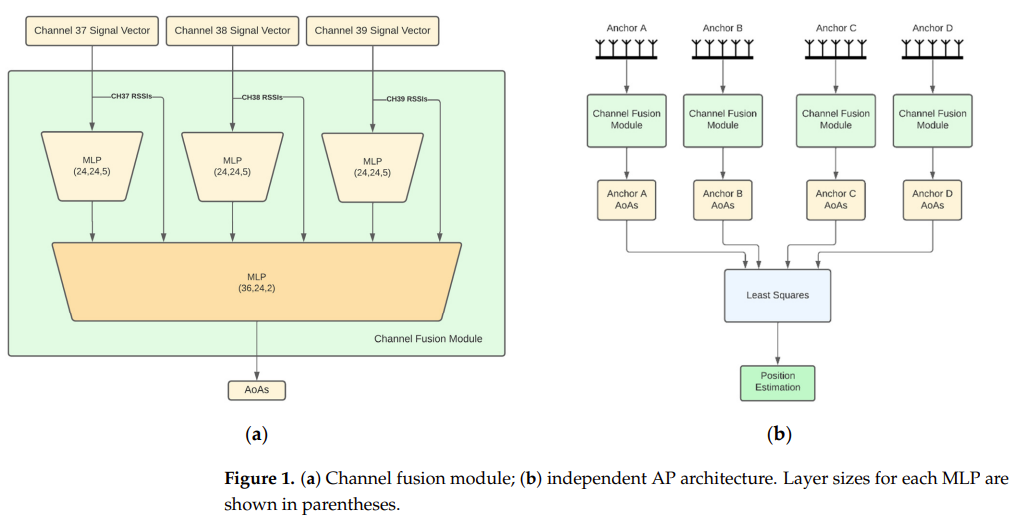
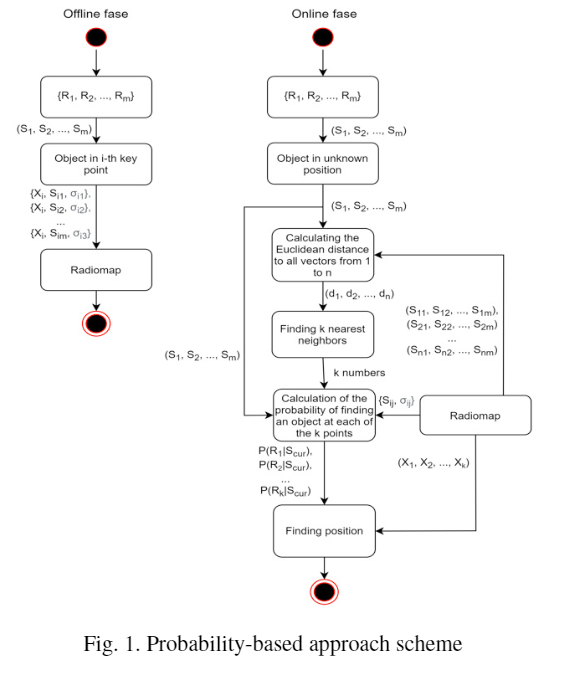
Analysing sensor data from Bluetooth beacons using machine learning involves several steps, from data collection and preprocessing to model development and deployment. Here’s an overview of the process:
Step 1: Data Collection
The first step in analysing sensor data from Bluetooth beacons is to collect the data. Beacons continuously broadcast data such as unique identifiers, signal strength (RSSI) and sometimes telemetry data like temperature an battery level. Sensor beacons also enable detection of a wide range of environmental and operational metrics. To collect this data, you need one or more receivers such as smartphones or gateways that can detect these signals and store and forward the data for further analysis.
Step 2: Data Pre-processing
Once data collection is complete, the raw data often needs to be cleaned and structured before analysis. This may involve:
- Removing noise and outliers that can distort the analysis.
- Filtering data to focus only on relevant signals.
- Normalising signal strength to account for variations in distance and transmitter power.
- Time-stamping and sorting the data to analyse temporal patterns.
Step 3: Feature Engineering
Feature engineering is sometimes critical in machine learning. For beacon data, features might include the average signal strength, or changes in signal strength over time. These features can help in developing models that understand patterns in data, such as identifying the trajectory of a moving beacon.
Step 4: Machine Learning Model Development
With pre-processed data and a set of features, you can train machine learning models to detect, classify, or predict. Common machine learning tasks for beacon data include:
- Classification models to determine the type of interaction (e.g. particular types of movement).
- Regression models to estimate distances from a beacon based on signal strength.
- Clustering to identify groups of similar behaviours or patterns.
Tools and frameworks like Python’s scikit-learn, TensorFlow or PyTorch can be used to develop these models.
Step 5: Evaluation and Optimisation
After developing a machine learning model, it’s important to evaluate its performance using metrics like accuracy, precision, recall and F1-score. Cross-validation techniques can help verify the robustness of the model. Depending on the results, you may need to return to feature engineering or model training to optimise performance.
Step 6: Deployment and Real-time Analysis
Deploying the model into a production environment is the final step. This means integrating the model into an existing app or system that interacts with Bluetooth beacons. The goal is to analyse the data in real-time to make immediate decisions such as sending notifications to users’ phones.
Read about our consulting services